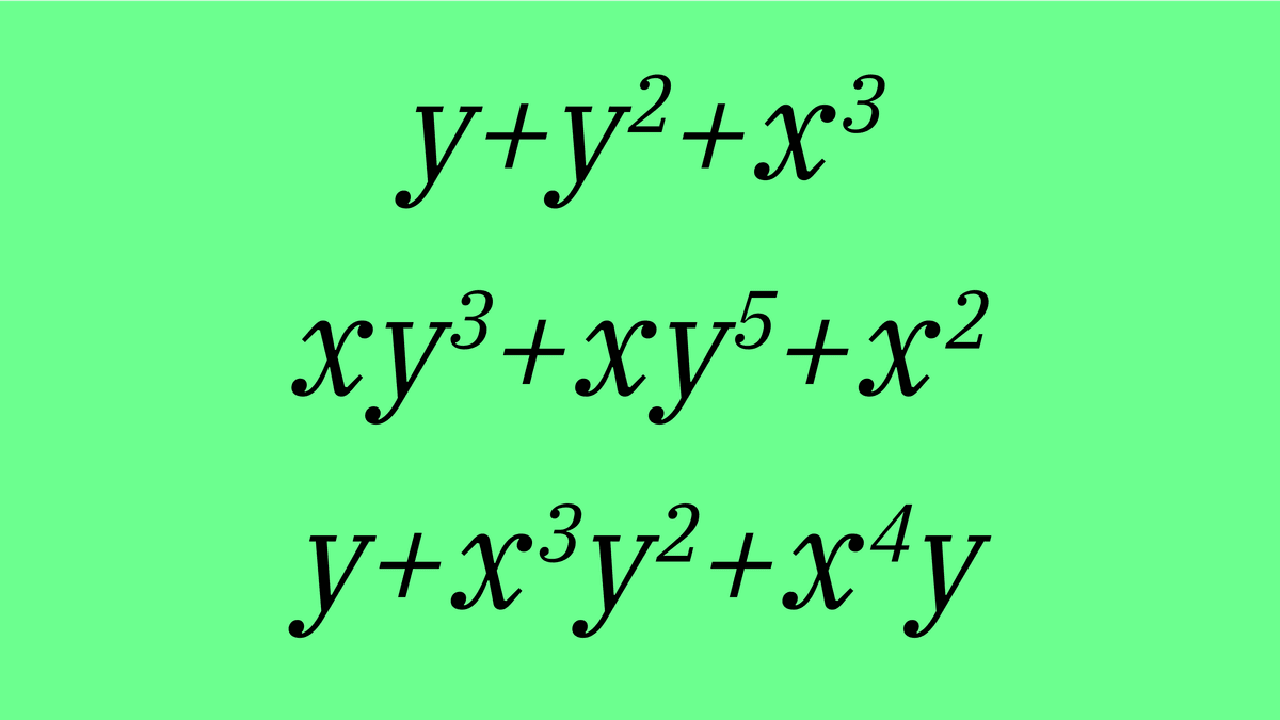
主要成果
IBMの研究者チームは、大規模言語モデル(LLM)が量子エラー訂正コードを効率的に発見できることを示す画期的な研究成果をarXivで発表しました。彼らが開発した進化的ワークフローは、数千もの潜在的なコードバリエーションを体系的に探索し、有望な候補を特定し、その特性を詳細に分析する能力を持っています。この成果は、古典的な人工知能と量子コンピューティングが互いに補完し、その進化を加速させる新たな道筋を開くものです。
技術・臨床詳細
この進化的ワークフローは、LLMが量子エラー訂正コードの設計空間を探索するための「ガイド」として機能することに基づいています。具体的には、LLMは既存の量子エラー訂正コードの知識や量子情報理論の原則を基に、新しいコードの構造やパラメータを提案します。次に、これらの提案されたコードは、古典的なシミュレーターや、将来的には実際の量子ハードウェア上でその性能が評価されます。評価結果はLLMにフィードバックされ、さらなる改良のための学習データとして利用されます。この反復的な最適化プロセスにより、LLMは従来の人間主導のアプローチでは到達困難だった、より効率的でロバストな量子エラー訂正コードを発見する可能性を秘めています。研究では、特定の性能基準を満たすコードを、はるかに短い時間で特定できることが示されました。
背景・業界文脈
量子コンピューティングの実用化に向けた最大の課題の一つは、量子ビットが環境ノイズに対して非常に敏感であるため、エラーが頻繁に発生することです。このエラーを効果的に訂正する「量子エラー訂正」は、大規模で信頼性の高い量子コンピューター(フォールトトレラント量子コンピューター)を構築するための鍵となります。量子エラー訂正コードの設計は、非常に複雑で計算負荷の高い問題であり、これまでは専門家による直感と試行錯誤に大きく依存していました。今回のIBMの研究は、古典AI、特にLLMがこの複雑な設計空間を効率的に探索できることを示し、量子エラー訂正技術の発展を大幅に加速させる可能性を秘めています。これは、AIが科学的発見を加速する新たなパラダイムの一部であり、AIと量子科学の間の協調が深まっていることを示しています。
今後の展望
LLMが量子エラー訂正コードの発見を支援するこの新しいアプローチは、フォールトトレラント量子コンピューティングの実現に向けた重要なステップとなります。より効率的で強力なエラー訂正コードの発見は、必要な物理量子ビットの数を減らし、量子コンピューターの構築コストと複雑さを軽減することにつながります。IBMは、このワークフローをさらに改良し、より複雑な量子システムや異なる量子ビットモダリティに対応できるように拡張することを目指しています。将来的には、AIが量子アルゴリズム、量子ハードウェア設計、量子材料科学など、量子コンピューティングの他の側面でも中心的な役割を果たすようになり、量子技術全体の進歩を加速させることが期待されます。これは、古典AIと量子コンピューティングが融合した新たな研究・開発時代の幕開けを告げるものです。








コメント